
So a little while ago I pointed out that Facebook is running a massive Grayhat Strategy to Rank for Longtail in the SERPs, essentially carrying out SERP Sniffing to an insanely large scale, with the view of potentially building a community driven Content Farm. Some really interesting questions popped to mind:
- How many keywords are they ranking for?
- How well are they ranking?
- What sort of traffic volumes would they get?
- What would the commercial value of that traffic be?
Not all of these are easy to answer, and may or may not be of interest. So I expanded my questions with:
- How can I check their Rankings?
So I had a rough answer. Scrape and Rank. In reality, this would not be possible without the Dark Art of Scraping Google Search Results.
Which kind of lead me to think, this is a pretty simple, yet good method of referencing rankings. However scraping need not be bad. Like any SEO technique, it can be used for both,good and evil.
- How can I use that technique for blackhat purposes?
- How can I use that technique for whitehat purposes?
So I have figured a way to answer SOME of my questions. I then asked myself:
Can I create a simple and rough version of my technique so that ANYONE can use and verify?
The answer was, yes, to an extent. The recipe would include:
- A ScrapingScript,
- A Rank Checker,
- A Spreadsheet
- A little time.
Summary: In the post below I demonstrate
- The potential extent to which Facebook is gaming the SERPs with crappy content
- The ability to use Scraping for both white and black SEO techniques

- Scrape results for: http://www.google.com/search?hl=en&q=site%3Afacebook.com%2F+%22Community+Pages+are+not+affiliated+with%2C+or+endorsed+by%2C+anyone+associated+with+the+topic This query ideally finds all community pages indexed from the Facebook domain.
- Capture the title tags: e.g “Association football | Facebook”.
- Export to excel, and edit field to delete all references to “Facebook” to get a spreadsheet of keywords to check.
- Grab the keywords and Rank Check for google .com
- Compile and sort by everything in positions:
- Pos 1
- Pos 2-5
- Pos 6-10
- Page 2
- Pos 21-50
- Pos 51-100
- Pos 101-200
- Not ranked
- Sort into pie chart, and analyse.
I scraped the first 600 results of the query, with the help of the awesome Richard Shove. Well I had to strip 8 keywords for non eligibility / repeat. Also, when ranking, I only considered ranks up to the first 200 results. And I define a good rank to average rank as anything in the top 50.
What did I find? The ranking data makes good reading, even for such a small dataset:
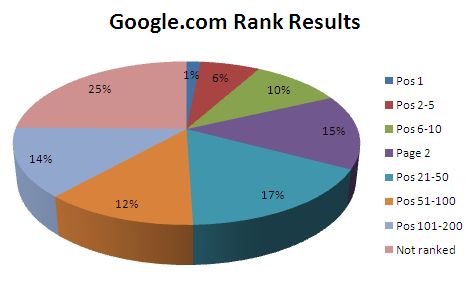
The data shows that of my keywords selected, only 25% weren’t ranked in the top 200 positions. Of the same data set, 17% ranked on page 1 of the SERPs.
Now lets look at that in theoretical terms. The query I used to generate this list indicates 119,000,000 results found.(That is One hundred and Nineteen MILLION results!!!)
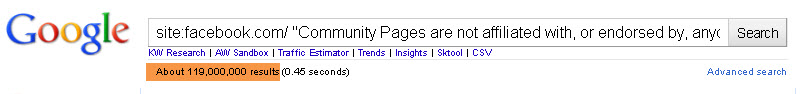
This is nowhere near the real number indexed. Why do I say that? Well you will get different indexed results depending on how quick google serves up the data to you… So refreshing the search gives me a different number indexed.

Lets just say for simplicities sake we have 100,000,000 pages indexed. If the data set above forms a working sample, then you expect 75% of these results ranking for the keywords necessary. 17% of the same dataset ranks in page one.
BIG picture? If (and note I say IF) my hypothesis holds, then these community pages that rank on page one equal in the region of 17,000,000. That is Seventeen MILLION folks. What traffic wold you hope to generate with 17 Million results on page 1 in google?
Not finished yet. The three most common variations on these pages title tags include:
- Community
- Interest
- Topic
Now cross reference any keywords that have these extentions added, in order to make a mid range keyphrase. I can only guess at the volume of page one rankings for those keyphrase variations.
At this juncture, I must point out that my friend Branko who is an awesome SEO Scientist, highlighted the fact that my methodology needs verification:
If I was you, I would take 2 more random sets of 600 queries and see if the distribution is similar. That way you can get an idea of how much fluctuations you have and how solid your data is. If you want to take it to the next level, there are statistical tests that can tell you whether your sample is representative of the population.
Now I was too lazy to do that to be honest. However I am sure those of you who are better at analysing and manipulating sata may be tempted. If so, let me know!
Now this is a massive massive invasion of the SERPs. And if I had the full X Million KW list to hand, I would love to have dug through it. But even my unscientific approach indicated something we British would call “corkers” . Danny Sullivan taught me a neat trick years ago, of comparing a high volume KW against another to get an indication of popularity. My list indicates that Facebook ranks well for “Singing”. Now lets use Danny’s technique:
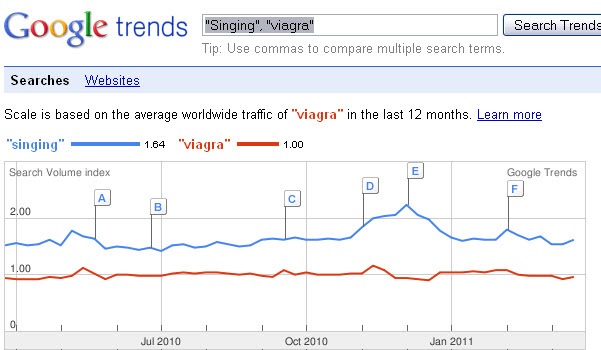
How cool is that? Singing gets more searches than Viagra. and here is a scraper page auto built by Facebook ranking for it. I include this because it indicates the potential volume of traffic that can be had by a large scale site that gets involved in Gray SEO techniques.
White Hat Scraping

When working on large scale SEO projects, for example Ecommerce SEO, competitive analysis is key in successful Long to Mid range strategy. Often we as SEOs tend to hone in on the “money” words and forget that the long tail not only exists, but is highly profitable.
I am not saying that we DONT target long tail keywords, but I dont think we competitively analyse this data.
So how do you use SERP Scraping for comptitive analysis? Do I have to really tell you? ![]()
- First off, scrape all the pages indexed for the competitor in question.
- Second, most common ecommerce SEO set ups use keyword splitters in the title tag. (They could be pipes, commas, arrows etc etc.) So use that knowledge to pull off keywords from your scraped data.
- Third, run a rank check on the full list.
- Four, compare against your own data. Where are the gaps?
- Profit.
Blackhat Scraping

Again, this is quite a simple use of that SERP rank data.
- Find a number of large sized sites with average or poor SEO
- Scrape all the pages indexed.
- You can use title tags, headings, etc to compile keywords from your scraped data.
- Third, run a rank check on the full list.
- Four, sort the data. Start with one word, two word, and continue sequencing till you get to 4-5 word combinations.
- Now you have an insanely large keyword list with rankings – sorted into keyword tails.
- I would then further sort these into “common” themes, e.g all car and auto related words / phrases together…
- Use an autoblog tool such as WPRobot to create thematic microsites which automatically pump out content based around your keyword sets. Add links where necessary.
- Profit?!
A serious Blackhat would probably know how to use Scraped SERPs for much much more than what I suggest above. However, I have chosen to demonstrate the lowest common denominator ![]() After all, this is a similar technique to the one I would say Mahalo used…
After all, this is a similar technique to the one I would say Mahalo used…

So there are a bunch of tools you can use to scrape, but to show you how easy it can be, see the link to the Google Scraping Script. (A big thank you to Dan Harrison of WordPress Doctors and William Vicary of Semto).
In case you think this is the only way to do this, here is another variant of the scraping script (thanks to Yousaf Sekander of Elevate Local).
This is just a limited version of the scraper and will take ages to pull out industrial strength data. If you are looking for something much more robust, try:
- Scrapebox
- 80 Legs
- Scrapy